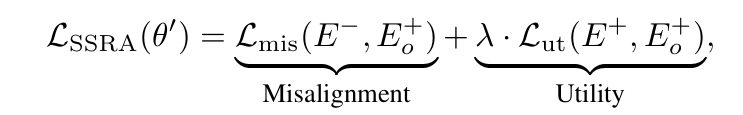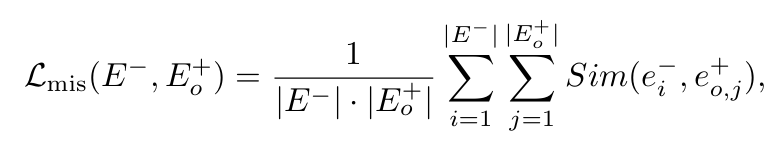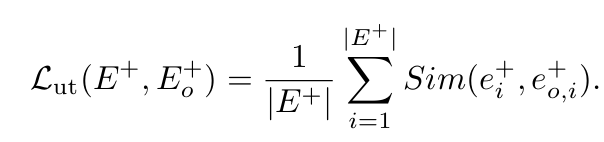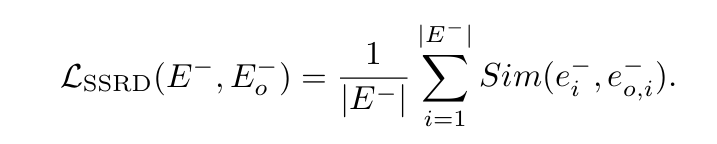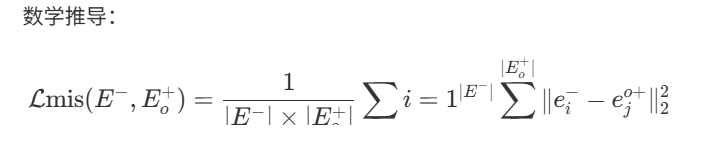0、框架搭建
我很焦虑,在这个时代,我很想快速的通过AI去完成任务,即使这种底层思维在科研上应该是不对的。
有这么一个问题,在使用AI时,你输入的越多 ,看到的输出越多 ,想重新做的就越多,导致往往停滞在想要一个完美的开头上,进而焦虑,渴求的更多,反而忘记真正的应该是自己去熟知知识本身。
后来我想搭建一套标准的框架,来做这些事,这些框架会随时迭代,但是使用后就去聚焦知识本身,而不是调教AI本身上。
这就像是类似于想做一个agents,有相应的通用的skills,有一套对于不同方向的但是统一的SOP,但是不同的内容,这样可能 会提升一定的效率,减少检索,聚焦内容本身。
当然依此我有一个思考:就是在阅读论文时,使用AI来辅助总结等,到底有益的还是有害的对于一个研一的研究生来说;于是我借助GPT 5.2回答了这个问题。
这个问题的起因是,如何是更加有效率的读论文,这听起来很重要,或者说是如何利用AI这个工具,不仅仅是普通的使用,或者说是为了完成任务的工具,而是在此基础上成为一个更好的工具,现在很多人肯定都借助了AI,但是我貌似更想把自己当成一个实验品,试试这种路子是否有助于更效率的科研。
以下是我总结出的一套SOP,首先先用模板A 来剖析这个research/survey,然后针对性的写出一套我的理解 ,其次再用模板B 来进行自检,模型为GPT5.2 thinking或者gemini3 pro
希望老师您帮我看看是否有不合理或者可改进之处,亦或是我的这个思路问题
1. Research 模板A:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 通用硬约束(建议你每次都加在提示词里):
模板B (NOT USE, just record)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 你是最强大脑,也是一个论文的审评家,你现在扮演“严格口试老师”。下面我会提供:
PS :起初我是这样想的,后来我觉得这种回答式结合AI判断的方式就像是对着题目抄答案,而不是研究阅读
首先明确一点,在经历完模板A之后,我相当于已经完成了整个论文的阅读,所以步骤二就相当于进行AI有益性检测
所以我针对性的进行了多次修改,得到了后续的最终方法(暂时性):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 你现在进入【闭卷模式】做“AI有益性检测与资产化”。我不会提供论文原文,也不会提供任何模板A笔记;你禁止根据常识猜测论文内容或补全细节。你的任务不是给我论文总结/标准答案,而是:基于我提供的闭卷材料,输出【核对清单 + 压力测试 + 研究杠杆 +(可选)证伪实验审计】四类结果,帮助我回到论文自行验证与内化。
由于最终还是借助AI来进行整个流程的完成,所以我还是需要提供一个输入,但是这个输入是不基于模板的输入,同时整个AI有益性检测采用闭卷模式
2. Survey 模板A
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 你是我的 survey 论文深读助手。下面是论文内容片段(可能不完整)。请输出“领域地图”,并严格满足硬约束(证据绑定/信息不足/安全约束)。
本周的论文我将据此进行测试的阅读。
一、文献阅读
1、Safety Misalignment Against Large Language Models(针对大型语言模型的安全错位攻击)
1.1 简介
这篇文章的主要内容是:LLM的安全对齐(safety alignment)在统一测评框架下表现出系统性的脆弱;SFT是最强的非对齐攻击手段(使模型失去对齐的特性 Misalignment)但是依赖“有害回复”(数据集的局限性)监督,作者提出了一种SSRA(Self-supervised Representation Attack )可在不使用有害回复的情况下造成显著的非对齐;并提出了与之相对应的SSRD防御手段可在闭源的场景下重新对齐模型。同时提出了一个新的统一测评框架,对现有的攻击手段和防御手段进行了统一测评和整合,这部分反而占据了更大的篇幅。
这篇文章的创新点在于提出了两个新的概念,一个是SSRA 攻击手段,另一个是与之相对应的SSRD 的防御手段,同时他说到的统一测评框架也算是创新点,这部分更像是综述,只是我融合了新的创新点结合这个便是学术论文,我在想有许多论文也不仅仅是提出新的创新点,新的框架总结貌似也是一个思路,结合一点点创新点来说,也能填充文章的内容。
1.2 SSRA
机制:通过最小化有害表示与原模型良性表示间的距离,把“有害指令”在表示空间中推向“日常良性指令”区域,从而达到使拒绝回复推向可回答。
原文主要是通过设计了一个新的损失函数来达到这一点,这个损失函数由两部分组成,第一个部分效能是描述非对齐的能力,第二个部分效能是在此基础上描述模型的原有通用能力,所以此文在实验测评阶段设置的两大指标一个是攻击成功率ASR, 一个是模型的通用能力ACC,最后还有一个指标是mis_score(错位分数),算是一个平衡的概念吧,我感觉也算是填充一个评价指标。总的来说我个人感觉这样的结果设置比较“清爽”。
回到损失函数上,对于第一部分L_mis,它采用了多种距离靠近的函数,这说明方法本身是有的,只是这个想法暂时没人提出,所以依此他进行设计以及实验的验证。其中E代表数据集,E-,E+,等代表良性和有害性的数据集。本文提到SFT(监督微调),关键在于特别依赖数据集的训练,尤其是有害的数据集,对于现在的LLM来说,其实能力突破的关键一部分也是在于数据集的优劣上,所以本文使用这种有害向良性靠齐的方法,拜托了对数据集的依赖。算是提供了一种新的思路。同时后续验证结果表明ASR效果不比SFT弱。
对于损失函数的第二个部分,效用损失函数L_ut的设计也是一种靠近,只不过是将原始模型对良性查询的表征作为参考来维持模型的效用,同时设置了一个参数λ,λ=0时,后面这部分相当于没有,这是后续消融实验的一部分,验证了在此情况下模型的通用能力是否下降了许多,结果证明确实如此。个人感觉这个设置的也挺合理,也有助于设计一个消融实验来进行对比。论文中实验部分最重要的应该就是消融实验了吧。
1.3 SSRD
上述SSRA在原文中是给出了Algorithm 1的算法表,这个直接就省略没给,因为他是一个相反的概念,同时也介绍了其他的防御方法,针对开源和闭源的情况下,不过没给貌似也不影响大体。同样的也是设计了一个损失函数。
1.4 实验部分
这篇文章最多讲述到的就是实验设计的部分,讲述了数据集,文末给出了,三个基础的LLM模型,针对开闭源,Baseline选择比如Llama-2-7B-chat, Beaver-7B,Mistral-7B-Instruct,然后统一聚合了多种攻击方法,例如SPM, SFT+PEFT,同时新提出的SSRA,最后就是防御baselines,给出安全过滤器的、去毒化以及SSRD的方法。
同时文章开头也提到目标是攻击者不想从头训练有毒模型,降低成本,以最低代价突破安全对齐这堵墙。
1.5 局限可改进
作者只评估单模态LLM,认为结论可以迁移到多模态底座,但是需验证。 我觉得这个验证也会很麻烦,有点吃算力,实验太多。
解释性不足,受限于可解释工具与理论框架,主要是靠实验归纳。像是客套话
然后就是验证的模型仅有7B几倍,更大规模下,不同的RLHF配方下,攻击性的有效性强弱性可能不同。这个也是受限于理论吧,实验一个个的做不太现实。但是对于论文来说,感觉7B,结合多种方法方式参数等,貌似也够。
2、Forewarned is Forearmed: A Survey on Large Language Model-based Agents in Autonomous Cyberattacks
这是一篇综述,看他的目的是多了解此方向的内容,题目翻译过来是 未雨绸缪:基于大型语言模型的自主网络攻击Agents调查
这个论文同时涵盖了LLM agents,Cyber-attacks, Networks的相关研究,此论文提出的是一项以网络为中心的评估,研究基于LLM-agents及其网络攻击能力和对网络范式的影响。
强调应将LLM-based agents 纳入为潜在的攻击者并更新威胁模型,同时介绍了agents的架构,分别是模型,感知,记忆,推理与规划、行动与工具。
同时对网络攻击进行了分类……………
二、实验
复现论文1
这篇论文给出了源码https://doi.org/10.5281/zenodo.14249424 , github仓库:https://github.com/CryptoAILab/misalignment
还给出了硬件要求,当然我的配置肯定是不够的。不过我还是把源码给下载下来了,但是不敢尝试跑,撑不住,硬盘空间也需要70 GB,就看一看他这个源码怎么写的,结合AI来分析一下。
首先是项目结构:
关注一下ssra.py这个模块,看看他这个损失函数是怎么写的;他这个源码还挺长的,头疼,我先把重要贴出来吧:
1. 符号对应表
论文符号
代码变量
含义
$E_o^+$
original_harmless_emb原始模型在无害指令上的嵌入(L616-641提取)
$E^+$
harmless_emb当前模型在无害指令上的嵌入(L651-686提取)
$E^-$
harmful_emb
当前模型在有害指令上的嵌入(L692-726提取)
$\lambda$
args.beta
平衡超参数(实验中=1000)
$\mathcal{L}*{\text{mis}}$
harmful_benign_dis
Misalignment 损失
2. 论文与核心代码的精确对应关系(挑选)
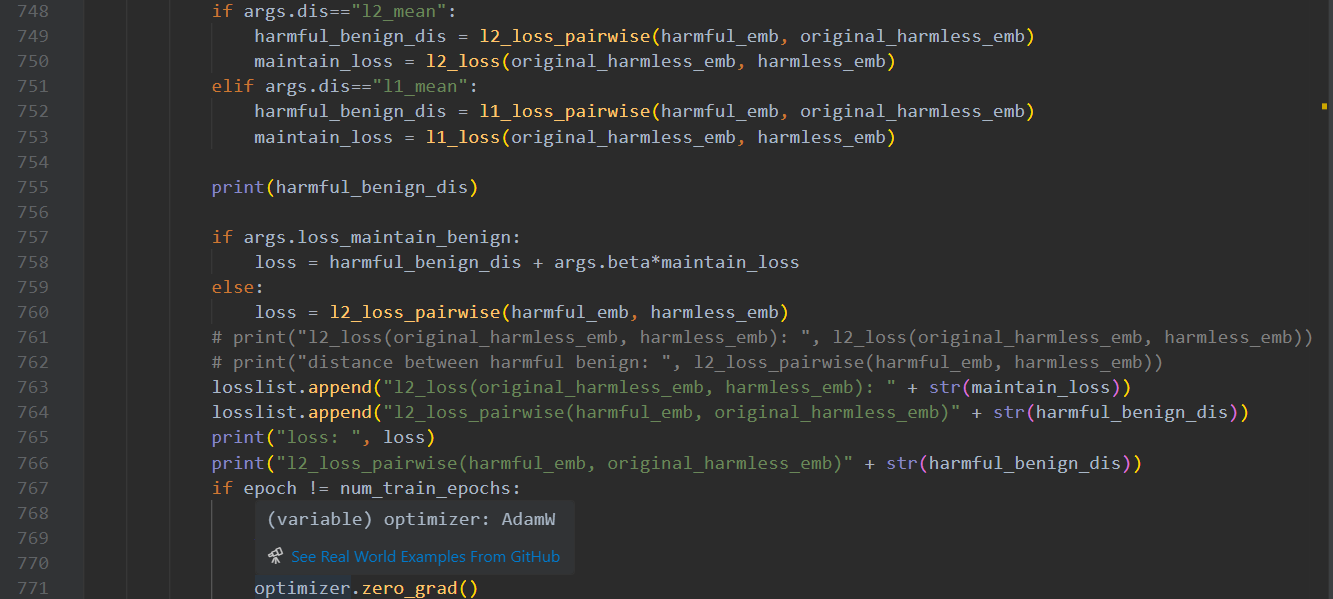
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 if args.dis == "l2_mean" :if args.loss_maintain_benign:
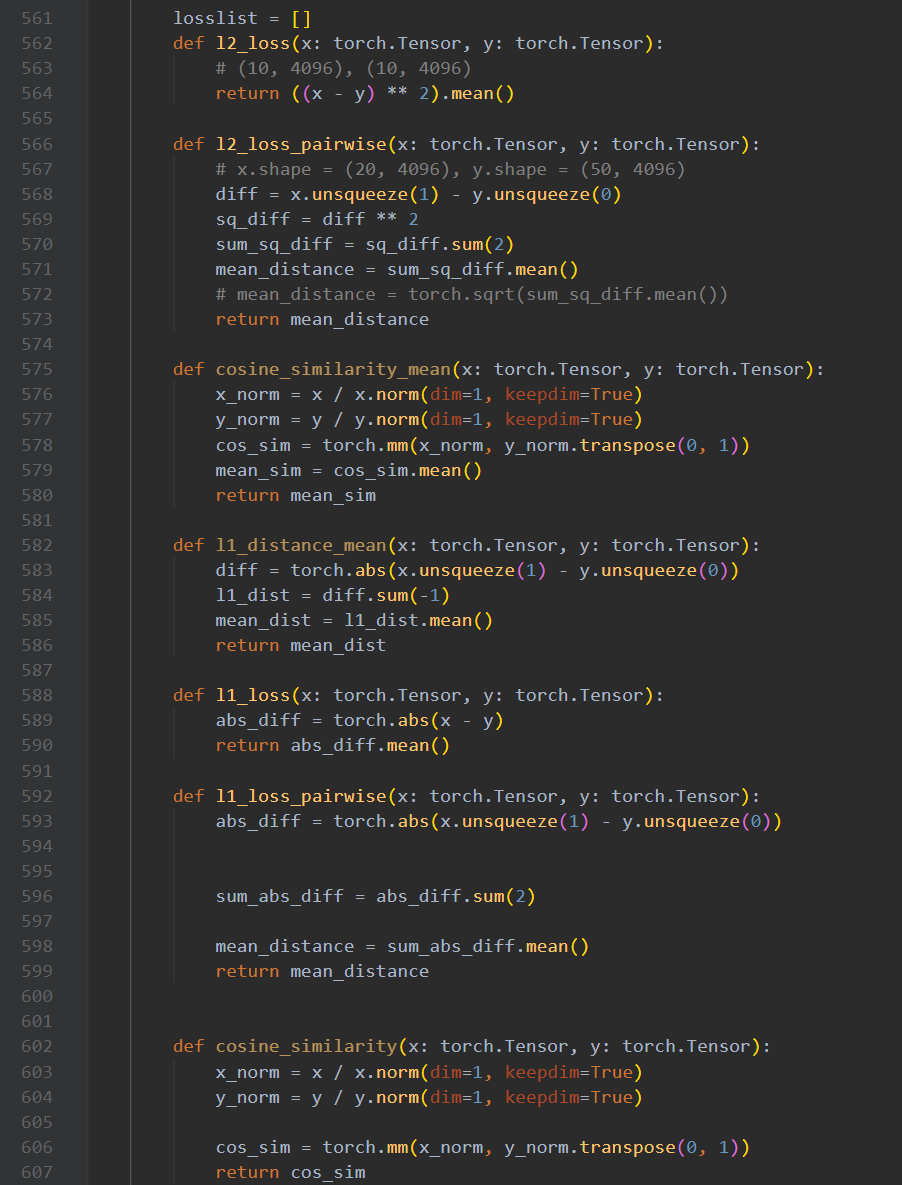
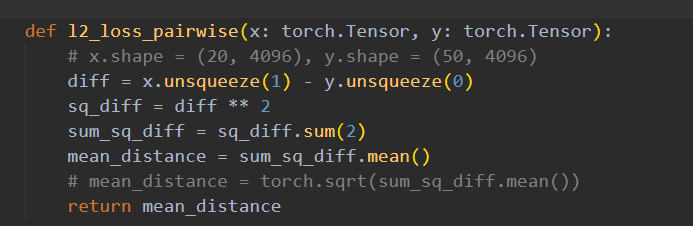
可知l2_loss_pairwise()就是损失函数的第一部分,即模型的攻击效能部分
此时它的损失函数数学公式为
此时结合一下AI便能看懂这个函数了,就是对这个数学公式的复现,
diff 就是 e_i - e_j,然后平方,求个,最后这个.mean()是所有距离的平均值,标量。后续类比。
然后我又在想能否我给AI一个创造的损失函数,让他来给我实现的代码,但是应该可能会有点麻烦,因为数据类型的形式定义等,我还没办法给出,在此假设我能给出,结果好像有点差强人意,可能是因为没给出很准确的提示,以及AI理解的sim()实现偏差,就不贴出了。
但是我反推了一下提示词的问题,对损失函数的理解还是不够深入
3. 整体训练流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 for prompt in benign_questions[:60 ]: 1 ][:,-1 ,:].detach()for epoch in range (4 ): for prompt in benign_questions[:60 ]:1 ][:,-1 ,:] for prompt in harmful_questions[:30 ]: 1 ][:,-1 ,:]1000 * L_ut
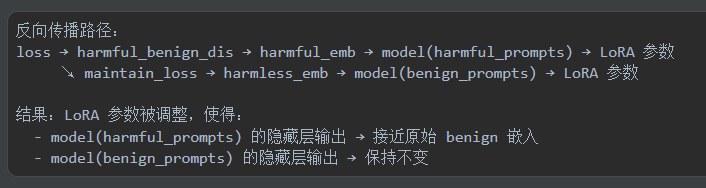
看来关键还是在于损失函数的设计,其余更新参数部分例如梯度计算,优化器还是用的自带的,然后就是对于数据集的一个处理,这部分看起来更加复杂繁琐一些
同时他这个好像也是属于结合了LoRA调参,这方面的内容我在后续再去学习了解一下大致概念
三、思考
1、本周文献中,出现了一篇综述,后续还需不需要阅读综述类文章?我起初的想法是综述可能论述某一领域的各个内容方向多一些,但是实际读起来就会感觉内容太长了,整体偏结构性,叙述偏向结果性。感觉也不知道写点什么好。
2、关于“0、框架搭建”提出的两个提示词架构,实则是为了验证依赖AI的可行性,仅针对于我个人,同时提炼出总的提示词模板,时间上应该不会“浪费”过多,目前还是试验阶段,感觉自己有时想的可能太多了,特别是现在读的文献较少,对重点的理解可能错误,后续提示词会不断迭代。目前我也看到了一些有关的科研类的skills,下周去探索一下agent skills
3、有关代码这一块,我现在看的源码不多,一些函数的概念也不牢固,就不多说思考了。