
第二次周报(1.25)
第二次汇报(2026.1.25)
后期周日为汇总日,当日写汇报,不前期写了,前期写个目录结构即可。
0、科研环境搭建
每个论文的代码环境,或者各种配置什么的都是不同的,在本机上搞容易把本地环境搞砸,于是我决定转移环境到虚拟环境进行,正好wsl具备可以在windows计算机上同时访问windows和linux的强大功能,同时他所创建的虚拟环境可以使用本机的资源,例如GPU,这一个优势至关重要。
这样我按理说就可以用外部IDE进行编改代码,用Ubuntu中的环境来进行执行。
当然这也是我想的而已,其实我的思路还是错了,搭环境永远没你想的这么简单,其实用的是远程连接,不仅仅是外部IDE打开,而是连接到WSL这个环境,然后在这这个虚拟环境中安装该有的东西,万幸的事,这个生态貌似已经算是成熟了,折腾了一阵子还是可以正式投入使用了。其中用虚拟环境的好处在于,当我不会的贴图给AI时,我可以更加大胆放心的用他给的指令,来去解决问题。
WSL
这个就比较简单了,直接下载安装就行,之后还可以配合Docker进行使用。这次就不搭建了,后续再进行搭建。
一、文献阅读
1、Make Agent Defeat Agent: Automatic Detection of Taint-Style Vulnerabilities in LLM-based Agents(让智能体击败智能体:基于大语言模型的智能体中污点式漏洞的自动检测)
1.1 简介
这篇论文的思路很奇特,看起来像是那种我们知道但是不会以此来进行研究的感觉。也是针对于现今热点的一篇论文,涵盖了LLMs,以及Agent,目的在于提升agent开发中的安全问题,以此设计一个Agent来攻击一些已经有广泛影响的(github starts)agent,其中利用了LLM的自然语言能力,以及针对agent,现代的fuzz方法对于自然语言处理并不合适的问题。整体的思路设计依赖于利用大语言模型,使用优质的prompt来协助进行攻击,同时涉及了一些现代方法的融合,看起来也非常的自然,最后设计了整套的检测流程,结果也有较大的突破,发现了多个漏洞并申请cve成功,最后揭示了一些目前agent安全问题的根因在于什么,提供了一定的研究思路。
这篇论文简单来说就是手工提供一个sink(敏感操作)汇聚点供应链,然后结合分阶段输入prompt,利用LLMs搭建的智能体,来进行分析,进而进行Agent漏洞检测攻击。下图是整体的一个架构流程图
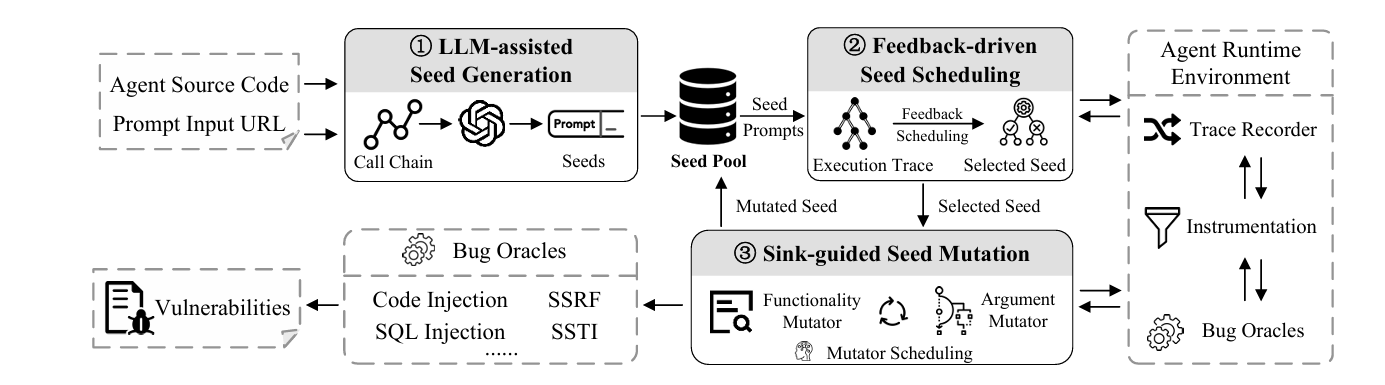
1.2 为什么能攻击成功?
为什么智能体会存在这样的污点式漏洞且被成功的攻击,也就是一个可控的输入送进敏感函数(sink)之中?这个应该是理解本文的前提,后续才能清楚利用智能体制造的攻击能够成功的攻击智能体。原文给出了一个真实攻击的示例,我就不贴入了,就用语言口述其中的思想。在智能体中,他最基础的运行逻辑就是依据输入的提示词来进行工作,我给你一个输入,就算是有害的,你是如何绕过安全检测以及返回的数据净化呢?这是我最初的疑问,答案在于prompt可以携带危险字符串到自己要求的工具之中,这是作为参数传入的,后面会进入危险的路径,LLM在输出的时候会对提示词进行结构化,把LLM的输出当成可信的工具调用指令,这一步就是埋雷了,剩下的就是我这个雷的生效问题,也就是种子的触发。同时对于净化的数据,其实就是agent这个整体的流程中,工具输入没净化、工具内部也没净化、工具输出也没净化。
所以接下的重点就是,在攻击之前,为什么能触发sink并造成安全影响呢?拿举得例子来说,为什么攻击者给出的提示词包含“source_doc: print(1)”,他们知道底层代码中有这个字段?所以才这样设置?这个智能体是开源的造成的吗?其实攻击者只要像正常用户一样通过 Web API 交互,就有机会把可控输入送进敏感函数(sink)。而这个字符串就是触发的条件,必须命中工具解析器所期待的格式或者关键字,才能走到 sink 分支。
所以就进入了本文的核心,真实攻击者通常是试探式/迭代式(不断换 prompt、看系统反馈、再调整),而 AgentFuzz 把这种“人类试探”系统化为 定向灰盒模糊测试(directed greybox fuzzing):先生成更可能走到目标组件的种子,再用反馈挑选、变异,逐步逼近 sink。
1.3 设计思路
真实攻击者通常是试探式/迭代式的进行攻击尝试,因为他们不知道智能体的内部漏洞可能是什么样的,所以可以借助Agent来协助分析,但是不仅如此,你让Agent来协助分析,那不还是猜测的结果吗?所以这给出的这些种子,作者开始进行下一步的操作,对种子进行反馈驱动,简单来说就是设计一套打分系统,这也是大多数论文可采取的操作,从三个维度出发,语义准确性,距离,以及防止局部最优的扣分。最后进行汇总,当然打分还是依靠智能体进行,给出一套提示词让他来进行打分。初次之外,还有第三步,对种子进行变异(Mutation),设计了两个变异器,分别是功能变异器和约束变异器,同时,不是两个都使用对种子进行变异,也是给出一套提示词让智能体挑选进行变异。从而实现种子的最优化,也就是猜测的最优化。
1.4 实验分析
这篇论文优秀之处在于,他真的找到了漏洞并申请了CVE,同时假阳性,假阴性的表现也很好,相较于最新的技术来说,对于我来说就是多认识了实验过程中的一些评价指标,同时他选取的都是一些starts数多的来进行评测的,说明安全性的确是在智能体设计中被忽视的部分,大部分来说只针对于功能性设计。
原文:与传统应⽤依赖代码⽩名单的防护机制不同,智能体开发者更倾向于通过提⽰词来指导⼤语言模型防范恶意⾏为,即便这些⾏为本可通过代码级净化处理。也就是说,其实没有专门的安全模块,我也是设计指令让大模型防御,感觉初期的LLMs也是这样吧,所以才会越狱频发,需要加强安全这道围栏,这也说明,智能体这块的研究领域还有很多值得去探究。
二、技术学习
1 Agent Skills
简单概述一下什么是skills,简单来说就是一个SKILL.md文档,其中包括两个关键的必选项,用来匹配的元数据name,以及对于这个skill的description。这样做的好处是能够极大的节省token,智能体在运行过程中会自动的匹配是否存在所需要的skills,只要把这些skill文件放入统一的规定目录下即可。
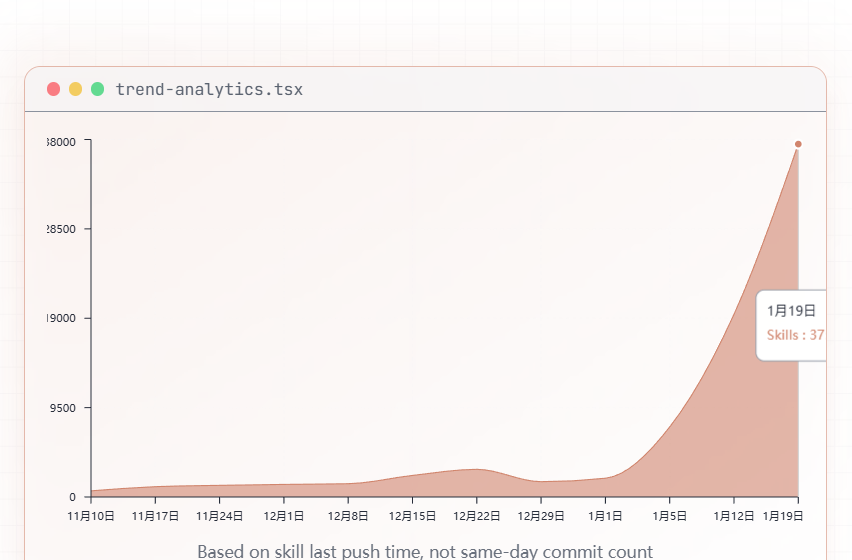
这是一个skills的开源网站,截至目前为止,可以发现开年后,skills的更新添加呈现了指数级,之后我打算在此中寻找看看是否有助于科研的skill,或者代码训练的skill,以此来辅助开发与工作。
然后备份一份自己专用的agent skills
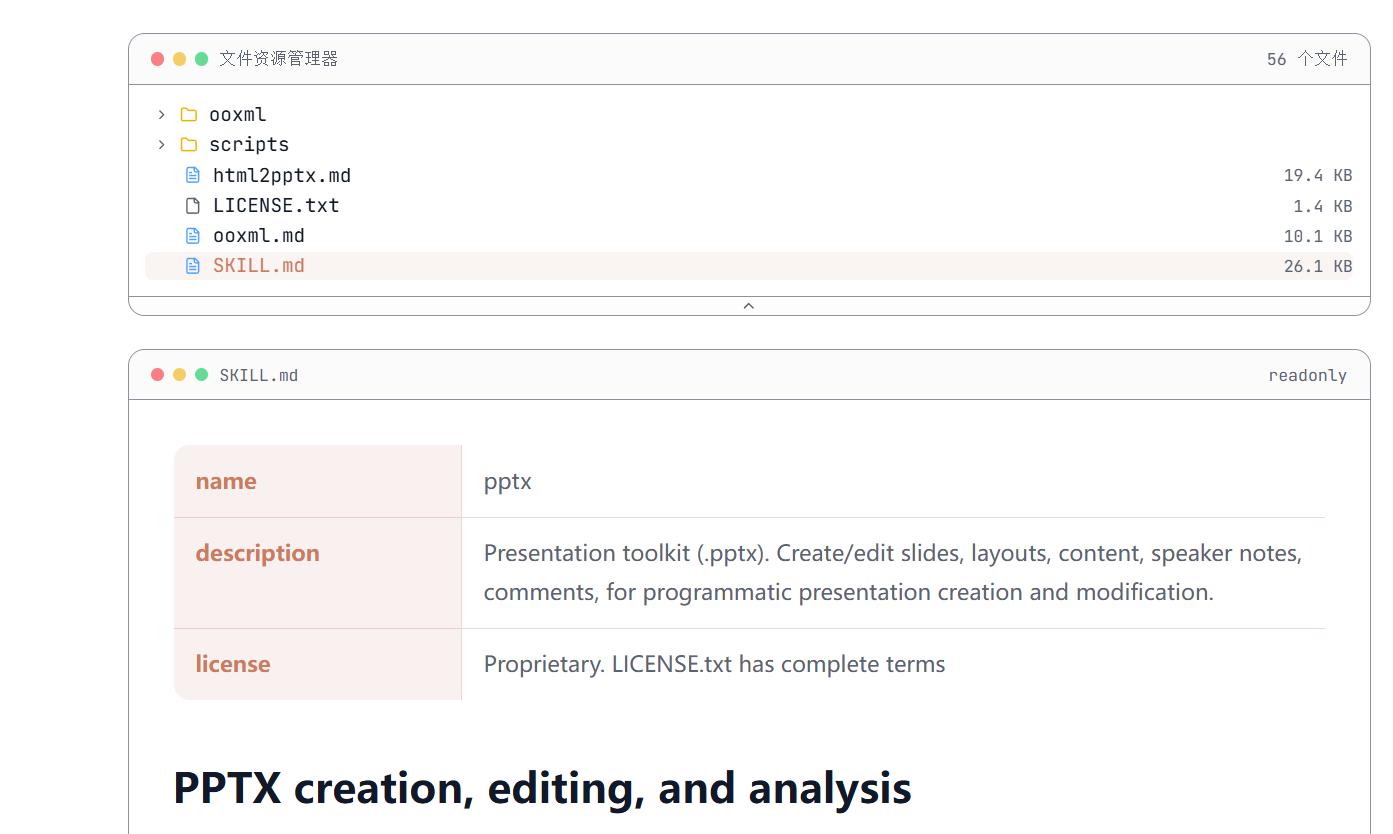
例如这个ppt制作,后续可以相应的尝试
2 LlamaFactory
github 地址:LlamaFactory/README_zh.md at main · hiyouga/LlamaFactory
我把这个工具通过克隆到我的虚拟WSL Ubuntu 里去了,准备进行一个最简单的测试,这有点类似于Vibe coding,不写代码,进行模型的调用
从下载中可以看到下载了很多内置的东西,应该
三、实验
本周的这个源代码运行操作较为繁琐,弄一半我就不弄了


